

Algorithmic Efficiency

Algorithmic efficiency refers to how effectively an algorithm performs in terms of time and space as the input size increases. It focuses on optimizing resource usage by minimizing the time an algorithm takes to run (time complexity) and the memory it uses (space complexity). Understanding efficiency helps in comparing different algorithms and choosing the most optimal solution for specific problems. Key concepts include Big O notation, which describes worst-case scenarios, and techniques like divide and conquer, recursion, and dynamic programming for improving algorithm performance.
Learning Objectives
For the topic “Algorithmic Efficiency” in AP Computer Science Principles, you should learn how to evaluate an algorithm’s performance based on time and space complexity using Big O notation. Understand the trade-offs between different algorithms, particularly in terms of best, worst, and average case scenarios. You should be able to analyze, compare, and optimize algorithms, focusing on improving efficiency through techniques such as recursion, iteration, dynamic programming, and memoization. Mastering these skills will enable you to design and implement effective solutions to computational problems.
Algorithmic Efficiency
Algorithmic efficiency refers to the measure of how effectively an algorithm performs in terms of time and space when processing input data. It evaluates the resources (time and memory) an algorithm consumes as it runs, particularly as the size of the input grows.
Key Concepts in Algorithmic Efficiency

Time Complexity
Time complexity evaluates the amount of time an algorithm takes to complete as a function of the input size (denoted as n). It describes how the runtime of an algorithm increases as the input grows.The most common notations to express time complexity are Big O, Big Ω, and Big Θ.
- Big O Notation (O): Describes the upper bound of an algorithm’s runtime. It tells you the worst-case scenario.
- Big Ω Notation (Ω): Describes the lower bound, or the best-case scenario for the algorithm’s performance.
- Big Θ Notation (Θ): Describes the exact bound, or the average case for the algorithm’s performance.
Common time complexities include:
- O(1) (constant time): The runtime doesn’t depend on the input size.
- O(log n) (logarithmic time): The runtime increases logarithmically as the input grows.
- O(n) (linear time): The runtime increases proportionally with the input size.
- O(n^2) (quadratic time): The runtime increases quadratically as the input grows, typical for algorithms with nested loops.
- O(2^n) (exponential time): The runtime doubles with each additional input size, typical in recursive algorithms.
Space Complexity
- Space complexity measures the amount of memory or storage an algorithm requires as it runs. This includes both the space used by the input data and the auxiliary space needed by the algorithm.
- Like time complexity, space complexity is also measured in terms of Big O notation.
- Some algorithms may trade time for space, and vice versa. For example, storing additional data in memory (increased space complexity) may reduce the time it takes to access or compute results.
Factors Influencing Algorithmic Efficiency
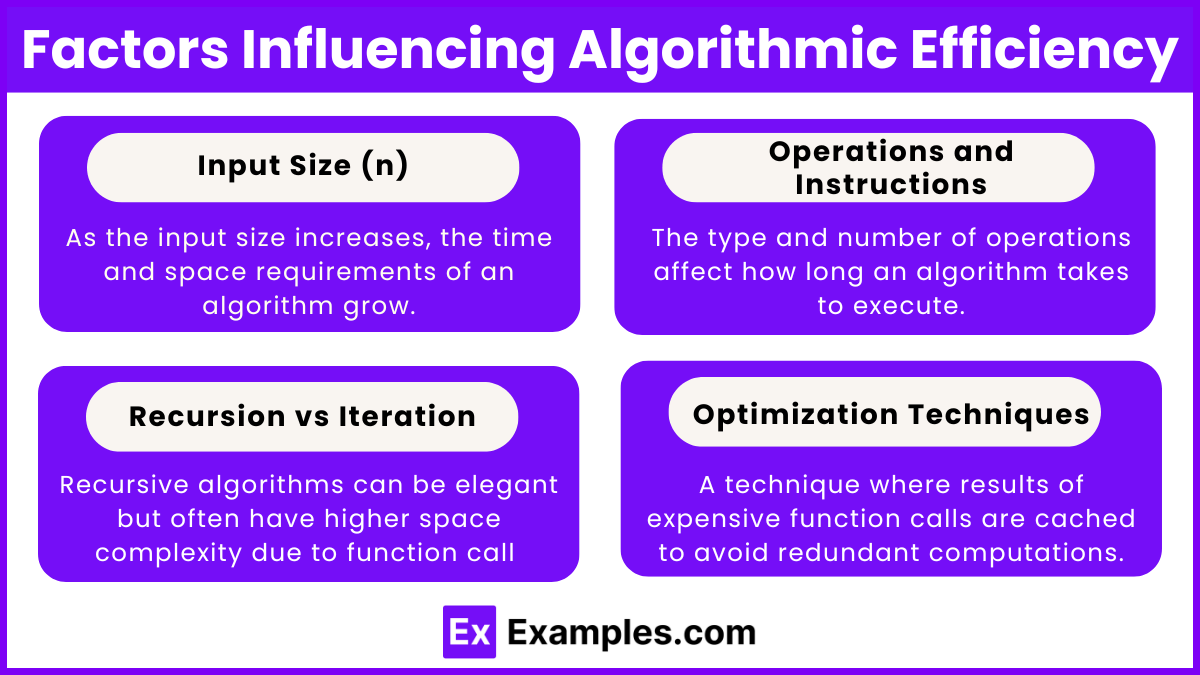
- Input Size (n):
- As the input size increases, the time and space requirements of an algorithm grow. Efficient algorithms handle large input sizes with minimal impact on performance.
- Operations and Instructions:
- The type and number of operations (arithmetic, comparisons, loops, function calls) affect how long an algorithm takes to execute. Reducing redundant or unnecessary operations improves efficiency.
- Recursion vs Iteration:
- Recursive algorithms can be elegant but often have higher space complexity due to function call overhead and the use of the call stack. Iterative solutions, when applicable, often reduce space usage.
- Optimization Techniques:
- Memoization: A technique where results of expensive function calls are cached to avoid redundant computations.
- Dynamic Programming: Solving problems by breaking them into overlapping sub-problems, storing their solutions to avoid recomputation.
- Divide and Conquer: Breaking the problem into smaller independent sub-problems, solving each, and combining results (e.g., merge sort).
Analyzing Algorithmic Efficiency

- Best Case, Worst Case, and Average Case Analysis:
- Best Case: The scenario where the algorithm performs the fewest possible steps.
- Worst Case: The scenario where the algorithm takes the maximum time to complete, often the focus of Big O analysis.
- Average Case: The typical scenario that falls between the best and worst cases.
- Comparison of Algorithms: Algorithms can be compared by their time and space complexities to determine which one is more efficient for specific tasks. For example:
- Linear Search vs Binary Search: Binary search has a time complexity of O(log n) compared to linear search’s O(n), making it more efficient for sorted datasets.
- Selection Sort vs Merge Sort: Selection sort has a time complexity of O(n^2) while merge sort is O(n log n), making merge sort more efficient for larger inputs.
Examples
Example 1: Binary Search
Binary search is a classic example of algorithmic efficiency, particularly in comparison to linear search. When searching for an element in a sorted array, binary search reduces the search space by half with each step, resulting in a time complexity of O(log n). This is highly efficient compared to linear search’s O(n), which examines each element one by one. As the input size grows, binary search dramatically outperforms linear search, making it ideal for large datasets.
Example 1: Merge Sort
Merge sort is an efficient, comparison-based sorting algorithm that uses the divide-and-conquer approach. It breaks down a list into smaller sublists until each sublist contains only one element, and then it merges them back together in sorted order. With a time complexity of O(n log n), merge sort performs better than O(n^2) algorithms like bubble sort or selection sort, especially for large input sizes. Its consistent time complexity makes it a preferred choice in various applications where sorting is critical.
Example 3: Dynamic Programming (Fibonacci Sequence)
Calculating the Fibonacci sequence using a naive recursive approach has a time complexity of O(2^n), as it involves redundant recalculations of values. However, by using dynamic programming and storing previously computed values (memoization), the time complexity can be reduced to O(n). This optimization highlights the importance of algorithmic efficiency, turning a previously inefficient algorithm into a much faster one by eliminating unnecessary computations.
Example 4: Quick Sort
Quick sort is another divide-and-conquer algorithm, with an average time complexity of O(n log n), though it can degrade to O(n^2) in the worst case when the pivot selection is poor. In practice, quick sort is highly efficient and outperforms other O(n log n) algorithms like merge sort due to lower constant factors and better use of memory (in-place sorting). Quick sort is frequently used in practice for general-purpose sorting due to its efficiency and versatility.
Example 5: Breadth-First Search (BFS) for Shortest Path
In an unweighted graph, BFS is an efficient algorithm for finding the shortest path from a source node to all other nodes. With a time complexity of O(V + E) (where V is the number of vertices and E is the number of edges), BFS explores each level of the graph systematically. This efficiency is essential in real-world applications like network routing, where BFS can quickly find optimal routes across large and complex networks.
Multiple Choice Questions
Question 1
Which of the following time complexities represents the most efficient algorithm for large inputs?
A) O(n)
B) O(n^2)
C) O(log n)
D) O(2^n)
Answer: C) O(log n)
Explanation: O(log n) represents logarithmic time complexity, which grows very slowly compared to the input size. It is more efficient than O(n) (linear), O(n^2) (quadratic), and O(2^n) (exponential). As the input size increases, algorithms with O(log n) complexity handle the data more efficiently, making them ideal for large datasets. This is why algorithms like binary search, which operate in O(log n), are much faster for large input sizes.
Question 2
Which algorithm is likely to have a time complexity of O(n^2)?
A) Merge Sort
B) Bubble Sort
C) Binary Search
D) Quick Sort (average case)
Answer: B) Bubble Sort
Explanation: Bubble Sort is a simple sorting algorithm that repeatedly steps through the list, compares adjacent elements, and swaps them if they are in the wrong order. Its time complexity is O(n^2) because in the worst case, it performs n passes over the entire list, each involving n comparisons. Other algorithms like Merge Sort (O(n log n)) and Quick Sort (O(n log n) average case) are more efficient for sorting larger datasets.
Question 3
If an algorithm has a time complexity of O(2^n), what does this indicate about its performance?
A) It runs in constant time, regardless of input size.
B) Its runtime doubles with every additional input element.
C) It runs in logarithmic time, making it suitable for large datasets.
D) Its runtime decreases as the input size increases.
Answer: B) Its runtime doubles with every additional input element.
Explanation: An algorithm with time complexity O(2^n) exhibits exponential growth, meaning that for every additional element in the input, the runtime approximately doubles. This results in very poor scalability, making it impractical for large input sizes. Such algorithms are often seen in problems involving brute force or recursion (e.g., solving the traveling salesperson problem). While efficient for small inputs, they become computationally expensive very quickly as the input grows.