60+ Decision Tree Examples to Download

A decision tree is a visual representation of decision-making processes in management, showcasing various choices and their potential outcomes. Each branch represents a decision or action, leading to further branches and eventual results. This method simplifies complex management decisions by breaking them down into manageable parts, making it easier to analyze and evaluate options. Widely used in fields like business, healthcare, and data science, decision trees help in optimizing management strategies, predicting outcomes, and enhancing problem-solving efficiency.
What is a decision tree?
A decision tree is a diagram that maps out decisions and their potential consequences, using branches to represent choices and outcomes. This visual tool simplifies complex decision-making by breaking down processes into manageable steps, aiding in analysis and optimizing strategic planning.
Examples of Decision Tree
- Loan Approval Process: Evaluates credit scores, income levels, and employment status to approve or reject loan applications.
- Medical Diagnosis: Determines a patient’s illness based on symptoms, test results, and medical history.
- Customer Support: Routes customer feedback based on issue type, urgency, and customer profile.
- Marketing Campaigns: Chooses target audiences based on demographics, past behavior, and engagement levels.
- Employee Promotion: Assesses performance, tenure, and skill levels to decide on promotions.
- Fraud Detection: Identifies fraudulent transactions by analyzing patterns, transaction amounts, and user behavior.
- Product Recommendations: Suggests products based on customer purchase history and preferences.
- Insurance Underwriting: Evaluates risk factors like age, health, and lifestyle to determine insurance premiums.
- Credit Card Approval: Assesses applications based on credit history, income, and debt levels.
- Sales Strategy: Determines sales tactics based on market trends, competition, and customer feedback.
- Hiring Decisions: Selects candidates based on qualifications, experience, and interview performance.
- Supply Chain Management: Optimizes logistics based on demand forecasts, inventory levels, and supplier performance.
- School Admissions: Decides student admissions based on grades, extracurricular activities, and test scores.
- Investment Choices: Evaluates investment options based on risk, return potential, and market conditions.
- Product Development: Prioritizes features based on user feedback, technical feasibility, and market demand.
- Retail Inventory Management: Makes restocking decisions based on sales data, seasonal trends, and supplier lead times.
- Restaurant Menu Planning: Creates menus based on customer preferences, ingredient availability, and cost considerations.
- Website Personalization: Customizes website content based on user behavior, preferences, and interaction history.
- Environmental Policy: Formulates policies based on environmental impact assessments, stakeholder input, and regulatory requirements.
- Game Theory in Sports: Determines strategies in sports based on player performance, opponent strategies, and game conditions.
Real-Life Examples of Decision Tree
- Loan Approval Process: Banks use decision trees to evaluate credit scores, income levels, and employment status to decide whether to approve or reject loan applications.
- Medical Diagnosis: Doctors use decision trees to diagnose diseases based on patient symptoms, medical history, and test results, guiding them through a structured diagnostic process.
- Customer Support Routing: Companies use decision trees to route customer service queries based on issue type, urgency, and customer profile, ensuring efficient handling of requests.
- Marketing Campaigns: Marketers use decision trees to select target audiences based on demographics, past behavior, and engagement levels, optimizing campaign effectiveness.
- Employee Promotion Decisions: Organizations use decision trees to assess employees’ performance, tenure, and skills to determine eligibility for promotions.
- Fraud Detection: Financial institutions use decision trees to identify potentially fraudulent transactions by analyzing transaction patterns, amounts, and user behavior.
- Product Recommendations: E-commerce platforms use decision trees to recommend products to customers based on their purchase history and preferences.
- Insurance Underwriting: Insurance companies use decision trees to evaluate risk factors such as age, health, and lifestyle to determine policy premiums and coverage.
- School Admissions: Educational institutions use decision trees to decide student admissions based on academic performance, extracurricular activities, and standardized test scores.
- Investment Decision Making: Financial advisors use decision trees to evaluate financial budgets based on factors like risk tolerance, potential returns, and market conditions..
Business Examples of Decision Tree
- Product Pricing Strategy: Companies use decision trees to determine optimal product pricing based on factors like production cost, competitor pricing, and customer demand.
- Customer Churn Prediction: Businesses use decision trees to predict which customers are likely to leave based on usage patterns, support interactions, and demographic information.
- Inventory Management: Retailers use decision trees to decide on restocking schedules and quantities based on sales trends, seasonality, and supplier lead times.
- Sales Lead Scoring: Sales teams use decision trees to rank potential leads by evaluating factors such as past purchases, engagement levels, and demographic data.
- Quality Control: Manufacturing companies use decision trees to identify defects in products by analyzing production variables and inspection results.
- Supplier Selection: Businesses use decision trees to choose suppliers based on criteria like cost, quality, reliability, and delivery times.
- Ad Campaign Optimization: Marketing teams use decision trees to optimize ad spend by analyzing performance data, audience engagement, and conversion rates.
- Project Management: Project managers use decision trees to decide on project timelines and resource allocation by evaluating task dependencies, risks, and team availability.
- Employee Retention Strategies: HR departments use decision trees to identify factors leading to employee turnover and develop retention strategies based on employee feedback and performance metrics.
- Market Entry Decisions: Companies use decision trees to evaluate new market opportunities by considering factors like market size, competition, regulatory environment, and potential ROI.
Decision Tree Examples in Data Mining
- Customer Segmentation: Businesses use decision trees to segment customers into distinct groups based on purchasing behavior, demographics, and browsing patterns.
- Fraud Detection: Financial institutions apply decision trees to identify fraudulent activities by analyzing transaction patterns, user behavior, and historical fraud data.
- Predictive Maintenance: Manufacturing companies use decision trees to predict equipment failures by examining machine usage data, maintenance records, and operational conditions.
- Credit Scoring: Banks and lending institutions use decision trees to assess the creditworthiness of applicants by evaluating factors like income, credit history, and debt-to-income ratio.
- Market Basket Analysis: Retailers employ decision trees to understand product purchase combinations by analyzing transaction data and identifying frequently bought-together items.
- Customer Lifetime Value Prediction: Companies use decision trees to predict the long-term value of customers by considering purchase frequency, transaction value, and customer engagement.
- Churn Prediction: Telecommunications and subscription-based services use decision trees to predict customer churn by analyzing usage patterns, customer service interactions, and billing information.
- Sentiment Analysis: Social media and marketing firms use decision trees to classify customer sentiment from text data, such as reviews and comments, based on linguistic features and word usage.
- Anomaly Detection: IT and cybersecurity firms use decision trees to detect anomalies in network traffic and system logs by analyzing patterns that deviate from the norm.
- Disease Prediction: Healthcare providers use decision trees to predict the likelihood of diseases in patients by examining medical history, genetic information, and lifestyle factors.
Decision Tree Algorithm Example
1. Data Collection – Gather and organize data relevant to the problem for building the decision tree.
2. Data Preprocessing – Clean and format data, handle missing values, and encode categorical variables.
3. Feature Selection – Identify and select the most relevant features for the model.
4. Splitting Criteria – Choose a criterion like Gini index or entropy to split the data at each node.
5. Building the Tree – Construct the decision tree by recursively splitting the data based on the chosen criterion.
6. Pruning the Tree – Remove branches that have little importance to reduce overfitting and improve model performance.
7. Model Evaluation – Evaluate the decision tree using metrics such as accuracy, precision, and recall.
8. Hyperparameter Tuning – Optimize tree parameters like max depth and min samples split to enhance performance.
9. Making Predictions – Use the trained decision tree model to make predictions on new data.
10. Model Deployment – Deploy the decision tree model for practical use in real-world applications.
Decision Tree Example in Machine Learning
1. Data Collection – Collect data relevant to the problem to be solved using the decision tree algorithm.
2. Data Preprocessing – Clean and preprocess the data, handling missing values and encoding categorical variables.
3. Feature Selection – Select important features that will be used to build the decision tree model.
4. Splitting Criteria – Determine the criteria (e.g., Gini index, entropy) for splitting nodes in the tree.
5. Building the Tree – Construct the decision tree by recursively splitting the dataset based on the chosen criteria.
6. Pruning the Tree – Prune the tree to remove less significant branches and reduce overfitting.
7. Model Evaluation – Evaluate the decision tree model using performance metrics like accuracy and precision.
8. Hyperparameter Tuning – Tune hyperparameters such as max depth and min samples split to improve model performance.
9. Making Predictions – Use the trained decision tree model to make predictions on new, unseen data.
10. Model Deployment – Deploy the decision tree model for use in practical machine learning applications.
Types of Decision Trees
- Classification Trees: Categorize data into distinct classes based on input features, helping in predicting discrete outcomes like customer segmentation.
- Regression Trees: Predict continuous values by splitting data into segments based on input features, useful in forecasting sales or prices.
- Categorical Variable Trees: Handle data with categorical outcomes, ideal for classification tasks involving non-numeric data like survey responses.
- Continuous Variable Trees: Manage special revenue funds‘ continuous outcomes, often used in regression analysis for predicting metrics like revenue or growth rates..
- Binary Decision Trees: Split data into two distinct groups at each node, simplifying complex decisions by focusing on binary choices.
- Multi-way Decision Trees: Divide data into multiple branches at each node, offering a more detailed analysis for complex decision-making scenarios.
- CART (Classification and Regression Trees): Combines classification and regression, using Gini impurity or variance to split data, applicable in both discrete and continuous outcome predictions.
- ID3 (Iterative Dichotomiser 3): Builds trees by selecting attributes that offer maximum information gain, efficiently classifying data into distinct categories.
- C4.5: Improves ID3 by handling both continuous and categorical data, using entropy to split data and prune trees for better accuracy.
- CHAID (Chi-squared Automatic Interaction Detector): Uses chi-squared statistics to split data, ideal for categorical data analysis and detecting significant interactions between variables.
- Random Forests: Combine multiple decision trees to improve prediction accuracy and robustness, reducing overfitting by averaging multiple model outcomes.
- Gradient Boosting Trees: Build sequential trees, each correcting errors from the previous ones, enhancing predictive accuracy for complex datasets.
- Decision Stumps: Single-level trees used in ensemble methods, providing simple yet effective decisions in boosting and bagging techniques.
- Extra Trees (Extremely Randomized Trees): Use random splits for decision nodes, increasing diversity among trees and improving ensemble model performance.
- Boosted Trees: Sequentially add trees to correct errors from prior models, achieving high accuracy in predictive tasks.
- Bagged Trees: Use bootstrap aggregation to create multiple decision trees, reducing variance and improving model stability.
- Model Trees: Combine decision tree structures with linear regression models at leaf nodes, a technique useful for handling complex relationships in data management.
- Randomized Trees: Utilize random feature subsets and splits to improve model diversity and performance in ensemble methods.
- Oblique Decision Trees: Split data using hyperplanes at an angle, allowing for more complex decision boundaries and improved handling of high-dimensional data.
Structure of a Decision Tree
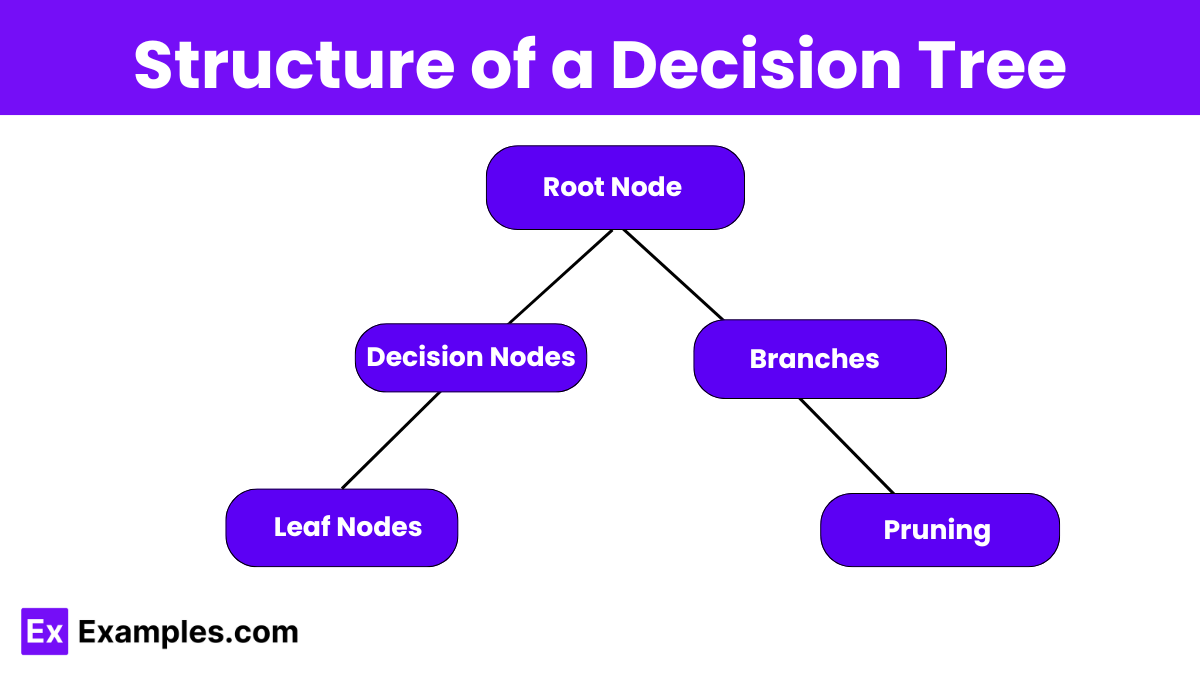
- Root Node: The starting point of the decision tree. Represents the entire dataset. Splits into two or more branches.
- Decision Nodes: Internal nodes that represent a decision or test on an attribute. Each decision node splits into further branches.
- Branches: Lines that connect nodes, representing the outcome of a test or decision. Lead from one node to another.
- Leaf Nodes (Terminal Nodes): End points of the tree. Represent the final outcome or decision. Do not split further.
- Splits: Criteria that divide data into subsets at each node. Based on specific attributes or conditions.
- Pruning: The process of removing parts of the tree that do not provide additional power in predicting target outcomes. Helps to prevent overfitting.
Decision Tree Terminologies
Node Types
- Root Node : The topmost node representing the entire dataset. All decisions start from here.
- Leaf Node (Terminal Node) : The end node representing a final decision or outcome. No further splits occur here.
- Decision Node : An internal node where a decision is made based on an attribute. Splits into branches.
Evaluation Metrics
- Gini Index : A metric used to measure the impurity or purity of a node. Lower Gini Index indicates higher purity.
- Entropy : A measure of the randomness or disorder within a set of data. Used to calculate information gain.
- Information Gain : The reduction in entropy or impurity after a dataset is split on an attribute.
Model Performance
- Pruning: The process of removing sections of the tree that provide little to no predictive power, to prevent overfitting.
- Overfitting : A model that fits the training data too well, capturing noise and leading to poor generalization on new data.
- Underfitting : A model that is too simple, failing to capture the underlying patterns in the data, leading to poor performance.
Tree Components
- Branch (Edge) : A connection between nodes, representing the outcome of a decision or test.
- Splitting : The process of dividing a node into two or more sub-nodes based on specific conditions.
- Binary Tree : A type of decision tree where each node splits into exactly two branches.
- Multi-way Split : A type of split where a node divides into more than two branches.
Tree Algorithms
- CHAID (Chi-squared Automatic Interaction Detector): A method that uses chi-squared tests to split nodes, often used for categorical data.
- ID3 (Iterative Dichotomiser 3): An algorithm used to create a decision tree by selecting the attribute that provides the highest information gain.
- CART (Classification and Regression Trees): A technique used for creating both classification and regression trees based on Gini Index or variance.
Why do we use Decision Trees?
- Easy to understand and interpret, even for non-technical users.
- Visual representation aids in explaining decisions to stakeholders.
- Handles both numerical and categorical data effectively.
- No assumptions about the data distribution.
- Suitable for complex data structures and relationships.
- Provides insights into the most important features for predicting the target variable.
- Applicable for both classification and regression tasks.
- Robust against outliers and noise.
- Pruning techniques control model complexity and prevent overfitting.
- Relatively fast to train and make predictions.
- Scales well with large datasets.
How Do Decision Trees Work?
- Start at the Root Node: The process begins at the root node, which represents the entire dataset.
- Splitting: The dataset is divided into subsets based on an attribute value test. This decision is made at internal nodes, where different conditions or tests on attributes determine the split.
- Branches: Each split creates branches, representing the outcome of the test. These branches lead to new decision nodes or leaf nodes.
- Decision Nodes: At each decision node, another attribute is selected for testing, and the process of splitting continues. This selection is based on criteria like Gini impurity or information gain to ensure the best possible split.
- Leaf Nodes: When a branch reaches a leaf node, a final decision is made. Leaf nodes represent the end result or class label for classification tasks or a continuous value for regression tasks.
- Stopping Criteria: The splitting process stops when one of several criteria is met, such as a maximum tree depth, a minimum number of samples per node, or when no further information gain is possible.
- Pruning: To prevent overfitting, pruning techniques may be applied. This involves removing parts of the tree that do not provide significant power in predicting outcomes, thereby simplifying the model.
Advantages and Disadvantages of Decision Trees
| Aspect | Advantages | Disadvantages |
|---|---|---|
| Interpretability | Easy to understand and interpret | Can become complex and less interpretable with many levels |
| Data Requirement | Requires less data preprocessing | Prone to overfitting if the data is noisy |
| Computational Cost | Efficient for small to medium-sized data sets | Can be computationally expensive with large data sets |
| Versatility | Handles both numerical and categorical data effectively | Biased towards features with more levels |
| Performance | Provides a clear indication of feature importance | May not perform well with linear separable data |
| Flexibility | Can handle multi-output problems | Sensitive to small changes in the data |
| Decision Making | Provides a visual representation of decision-making process | Can create over-complex trees that do not generalize well |
How are decision trees used?
They are used to model decisions and their possible consequences, including chance event outcomes, resource costs, and utility.
What is a root node in a decision tree?
The root node is the topmost node that represents the entire dataset.
What are leaf nodes?
Leaf nodes are the end points of a decision tree that represent the final outcome or decision.
What is splitting in a decision tree?
Splitting is the process of dividing a node into two or more sub-nodes based on specific criteria.
How does pruning affect decision trees?
Pruning removes parts of the tree that provide little predictive power, helping to prevent overfitting.
What is a classification tree?
A classification tree is used to predict categorical outcomes.
What is a regression tree?
A regression tree is used to predict continuous values.
What is overfitting in decision trees?
Overfitting occurs when the tree model becomes too complex and captures noise in the data, leading to poor generalization.
What are decision nodes?
Decision nodes are internal nodes where a test or decision is made on an attribute.
What is a binary decision tree?
A binary decision tree splits each node into exactly two branches.
Share :
